


In questa pagina sono raccolte alcune note sull'installazione e l'uso preliminare di InfluxDB 2. L'obbiettivo è avere un database ad alte prestazioni ed un'interfaccia WEB per raccogliere dati provenienti dai miei sensori IoT. Qui una pagina per Raspberry Pi (influxDB 1).
La scelta del server è caduta sui servizi messi a disposizione gratuitamente da Oracle cloud. In particolare la macchina di riferimento è un dual core ARM con 12 GB di RAM e 100 GB di disco; il sistema operativo è Ubuntu 22.04 LTS e il database InfluxDB 2.4, gli ultimi rilasci stabili nel momento della stesura di questa pagina. Ovviamente tale configurazione può essere adattata alle vostre preferenze e disponibilità.
L'installazione del sistema operativo è quella standard per sistemi server, quindi senza interfaccia grafica. Nel caso di Oracle cloud è fatta automaticamente nel momento in cui viene creata la macchina virtuale.
Il codice dell'ultima versione stabile si scarica direttamente dai repository ufficiali di InfluxDB (nota 1).
Occorre prima importare la chiave che firma il codice:
user@machine:~$ wget -qO- https://repos.influxdata.com/influxdb.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/influxdb.gpg > /dev/null
Quindi creare il file /etc/apt/sources.list.d/influxdb.list con la versione da installare:
user@machine:~$ export DISTRIB_ID=$(lsb_release -si); export DISTRIB_CODENAME=$(lsb_release -sc)
user@machine:~$ echo "deb [signed-by=/etc/apt/trusted.gpg.d/influxdb.gpg] https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list > /dev/null
Se tutto è andato bene:
ubuntu@DB:~$ cat /etc/apt/sources.list.d/influxdb.list
deb [signed-by=/etc/apt/trusted.gpg.d/influxdb.gpg]
https://repos.influxdata.com/ubuntu jammy stable
Ed infine procedere all'installazione vera e propria ed all'avvio:
user@machine:~$ sudo apt-get update && sudo apt-get install influxdb2
user@machine:~$ sudo systemctl enable --now influxdb
user@machine:~$ sudo systemctl status influxdb
● influxdb.service - InfluxDB is an open-source, distributed, time series
database
Loaded: loaded
(/lib/systemd/system/influxdb.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-06-27
06:34:59 UTC; 1min 12s ago
[...]
La prima configurazione può essere fatta da linea di comando:
user@machine:~$ influx setup
Sono richiesti alcuni parametri:
Le informazioni inserire, insieme ad altre generate automaticamente, possono essere viste con i seguenti comandi (nota 4):
user@machine:~$ influx config list
Active Name URL
Org
* default http://localhost:8086 VincenzoV.net
user@machine:~$ influx bucket list
ID Name
Retention Shard group duration Organization ID
Schema Type
xxx... Test
infinite 168h0m0s
123...
implicit
yyy... _monitoring 168h0m0s 24h0m0s
123...
implicit
ZZZ... _tasks 72h0m0s
24h0m0s
123...
implicit
Per conoscere il token necessario per interagire con in database (nota 2 e nota 4):
user@machine:~$ influx auth list
ID Description Token User
Name User IDPermissions
Xxx... xxx's Token XYZ... xxx
1234...
Il linguaggio di interrogazione di InfluxDB 2.x è Flux, diverso da quello usato con InfluxDB 1.x.
Per creare/elencare/cancellare i bucket possono essere usati i seguenti comandi (nota 4), specificando il nome o l'ID:
user@machine:~$ influx bucket create -n Test1 -r 24h
user@machine:~$ influx bucket list
user@machine:~$ influx bucket delete -n Test1
user@machine:~$ influx bucket delete -i 0b116e3b3f8fd3dd
user@machine:~$ influx bucket update -i f82165c3810c7c42 -n Test3 -r 96h
Vediamo come scrivere dati da CLI. L'esempio è relativo a misure ambientali (Measurement Ambiente), due sensori con Tag S1 ed S2, due Field relativi a temperatura ed umidità (nota 4):
user@machine:~$ influx write -b Test 'Ambiente,Sensore=S1 T=23.1,U=45.1'
user@machine:~$ influx write -b Test 'Ambiente,Sensore=S1 T=24.1,U=45.6'
user@machine:~$ influx write -b Test 'Ambiente,Sensore=S2 T=24.6,U=43.6'
Si noti che non è specificato alcun Timestamp; in questo caso è aggiunto automaticamente.
user@machine:~$ influx delete --bucket Test --start 2025-01-02T17:00:00Z --stop 2025-01-03T10:45:59Z
Il seguente script, installato sul server, legge da un sito di previsioni meteorologiche (nota 6) la temperatura esterna della sede della mia scuola e la inserisce nel Measurement Esterno:
user@machine:~$ nano /home/user/get_T.sh
#!/bin/bash
T=$(curl -s -L "https://api.open-meteo.com/v1/forecast?latitude=45.71&longitude=9.32¤t_weather=true"
| jq -r '.current_weather.temperature')
Data="Esterno,Sensore=OpenMeteo T=$T"
influx write --skip-verify -b Test "$Data"
user@machine:~$ chmode +x /home/user/get_T.sh
Se, per esempio, vogliamo fare una "misura" ogni cinque minuti possiamo inserire il comando in crontab:
user@machine:~$ crontab -e
*/5 * * * * /home/user/get_T.sh
L'interrogazione al database può essere fatta per esempio con il seguente comando, sebbene quanto visualizzato sia piuttosto "confuso":
user@machine:~$ influx query 'from(bucket:"Test") |> range(start:-100m)'
Alcune osservazioni sull'ultimo comando:
Alcune integrazioni esemplificative che permettono interrogazioni più dettagliate al database, tutte usabili in cascata:
I dati possono essere scritti utilizzando HTTP, conoscendo il Token. Di seguito un esempio che utilizza curl dalla macchina locale:
user@machine:~$ TOKEN=XYZ...
user@machine:~$ curl --request POST \
"http://localhost:8086/api/v2/write?org=VincenzoV.net&bucket=Test&precision=ns"
\
--header "Authorization: Token $TOKEN" \
--header "Content-Type: text/plain; charset=utf-8" \
--header "Accept: application/json" \
--data-binary 'Ambiente,Sensore=S3 T=25.6,U=44.6'
In genere non è una buona idea usare connessioni non cifrate sulle macchine in rete, soprattutto se collegate ad internet. In particolare è critica la trasmissione in chiaro del Token che, a tutti gli effetti, è una password. In alternativa è possibile usare un tunnel SSH oppure MQTT, con enormi vantaggi in termini di prestazioni.
Vediamo come configurare HTTPS per risolvere questo problema.
Innanzitutto serve un certificato che può essere autofirmato (come mostrato di seguito) oppure rilasciato da una'autorità di certificazione.
user@machine:~$ sudo openssl req -x509 \
-nodes -newkey rsa:2048 \
-keyout /etc/ssl/influxdb-selfsigned.key \
-out /etc/ssl/influxdb-selfsigned.crt \
-days 3650
user@machine:~$ sudo chmod 644 /etc/ssl/influxdb-selfsigned.crt
user@machine:~$ sudo chmod 644 /etc/ssl/influxdb-selfsigned.key
user@machine:~$ ll /etc/ssl/influxdb-selfsigned*
-rw-r--r-- 1 root root 1245 Jun 27 13:27 /etc/ssl/influxdb-selfsigned.crt
-rw-r--r-- 1 root root 1704 Jun 27 13:27 /etc/ssl/influxdb-selfsigned.key
Occorre quindi avviare influxDB per usare tale certificato:
user@machine:~$ sudo nano /etc/influxdb/config.toml
[...]
tls-cert = "/etc/ssl/influxdb-selfsigned.crt"
tls-key = "/etc/ssl/influxdb-selfsigned.key"
user@machine:~$ sudo systemctl restart influxd
L'accesso con curl è simile a quanto già visto: occorre solo specificare https nell'indirizzo e, nel caso di certificato autofirmato, -k:
user@machine:~$ TOKEN=XYZ...
user@machine:~$ curl -k \
--request POST "https://localhost:8086/api/v2/write?org=VincenzoV.net&bucket=Test&precision=ns"
\
--header "Authorization: Token $TOKEN" \
--header "Content-Type: text/plain; charset=utf-8" \
--header "Accept: application/json" \
--data-binary 'Ambiente,Sensore=S11 T=27.6,U=46.6'
Per utilizzare il comando influx occorre creare una nuova configurazione:
user@machine:~$ influx config create \
--config-name default_https \
--host-url https://localhost:8086 \
--org VincenzoV.net
--token $TOKEN \
--active
user@machine:~$ influx config list
Active Name URL
Org
default
http://localhost:8086 VincenzoV.net
* default_https https://localhost:8086
VincenzoV.net
user@machine:~$ influx query --skip-verify 'from(bucket:"Test") |> range(start:-100m)'
In genere l'accesso a InfluxDB è fatto da remoto utilizzando HTTPS. Prima di procedere occorre evidentemente aprire in entrata la porta 8086 del firewall (qui, per esempio, le istruzioni per Oracle cloud).
La scrittura dei dati è normalmente fatta con curl, specificando l'indirizzo IP del server:
user@machine:~$ TOKEN=XYZ...
user@machine:~$ curl -k \
--request POST "https://129.X.Y.Z:8086/api/v2/write?org=VincenzoV.net&bucket=Test&precision=ns"
\
--header "Authorization: Token $TOKEN" \
--header "Content-Type: text/plain; charset=utf-8" \
--header "Accept: application/json" \
--data-binary 'Ambiente,Sensore=S12 T=27.6,U=46.6'
Di seguito uno script bash di test, da installare su una qualunque macchina Linux, utile per riempire il database di dati reali (carico percentuale della CPU e sua temperatura) e per fare esperimenti. Ovviamente occorre adattarlo al proprio ambiente.
#!/bin/bash
TOKEN=XYZ...
URL="https://129.X.Y.Z:8086/api/v2/write?org=VincenzoV.net&bucket=Test&precision=ns"
echo "Press [CTRL+C] to stop.."
while :
do
CPU_USAGE=$(top -bn 2 -d 0.01 | grep '^%Cpu' | tail -n 1 | gawk '{print
$2+$4+$6}')
TEMP=$(expr $(cat /sys/class/thermal/thermal_zone3/temp) / 1000)
echo CPU = $CPU_USAGE - T = $TEMP
DATA=CPU_Usage,PC=vv-i7\ CPU=$CPU_USAGE,T=$TEMP
curl -k --request POST $URL \
--header "Authorization: Token $TOKEN" \
--header "Content-Type: text/plain; charset=utf-8" \
--header "Accept: application/json" \
--data-binary "$DATA"
sleep 1
done
L'amministrazione del database è possibile anche da browser, digitando l'indirizzo del server https://129.X.Y.Z:8086 (nota 3); l'immagine di apertura è la pagina principale per l'amministrazione del database.
Tra le cose che possono essere fatte vi è anche la rappresentazione grafica (nota 5) dei dati che, pur essendo esteticamente modesta, permette test veloci. Di seguito un esempio che visualizza i dati generati dallo script:
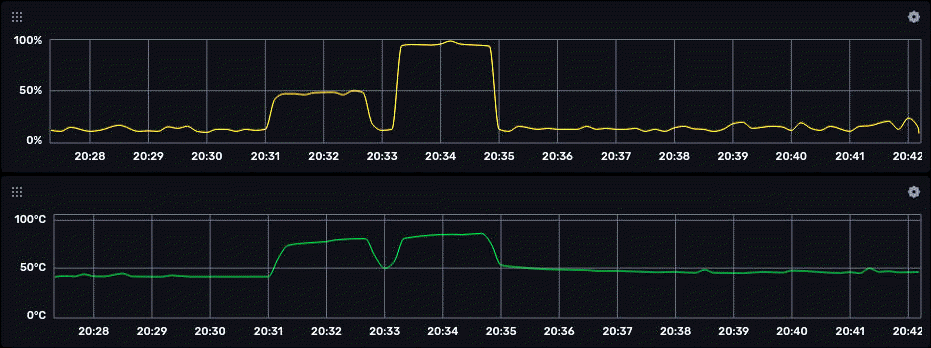
Per creare il grafico, dalla pagina principale:
Oltre a produrre il grafico graficamente (Query builder), viene mostrato anche il codice Flux di interrogazione (script editor):
from(bucket: "Test")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "CPU_Usage")
|> filter(fn: (r) => r["PC"] == "vv-i7")
|> filter(fn: (r) => r["_field"] == "CPU" or r["_field"] == "T")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
Pagina creata nel maggio 2022
Ultima modifica di questa pagina: 31 dicembre 2022
![]() Il taccuino tecnico - Permanentemente in fase di
riscrittura
Il taccuino tecnico - Permanentemente in fase di
riscrittura
![]()
Copyright 2013-2025, Vincenzo Villa (https://www.vincenzov.net)
![]()
Quest'opera è stata rilasciata con licenza Creative Commons | Attribuzione 4.0 Internazionale (CC BY 4.0)
